#---------------------------##----Model Construction-----##---------------------------#set.seed(1234)train_control <-trainControl(method ="cv", number =10)set.seed(1234)qda_model <-train(good ~ ., data = train, method ="qda", trControl = train_control)save(qda_model, file ="dataset\\qda.model_kfoldCV.Rdata")
Show/Hide Code
# Data Importload("dataset\\wine.data_cleaned.Rdata")load("dataset\\train.Rdata")load("dataset\\test.Rdata")# Function Importload("dataset\\function\\accu.kappa.plot.Rdata")# Model importload("dataset\\model\\qda.model_kfoldCV.Rdata")qda.predictions <-predict(qda_model, newdata = test)confusionMatrix(qda.predictions, test$good)
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 704 59
1 245 180
Accuracy : 0.7441
95% CI : (0.7183, 0.7687)
No Information Rate : 0.7988
P-Value [Acc > NIR] : 1
Kappa : 0.3834
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.7418
Specificity : 0.7531
Pos Pred Value : 0.9227
Neg Pred Value : 0.4235
Prevalence : 0.7988
Detection Rate : 0.5926
Detection Prevalence : 0.6423
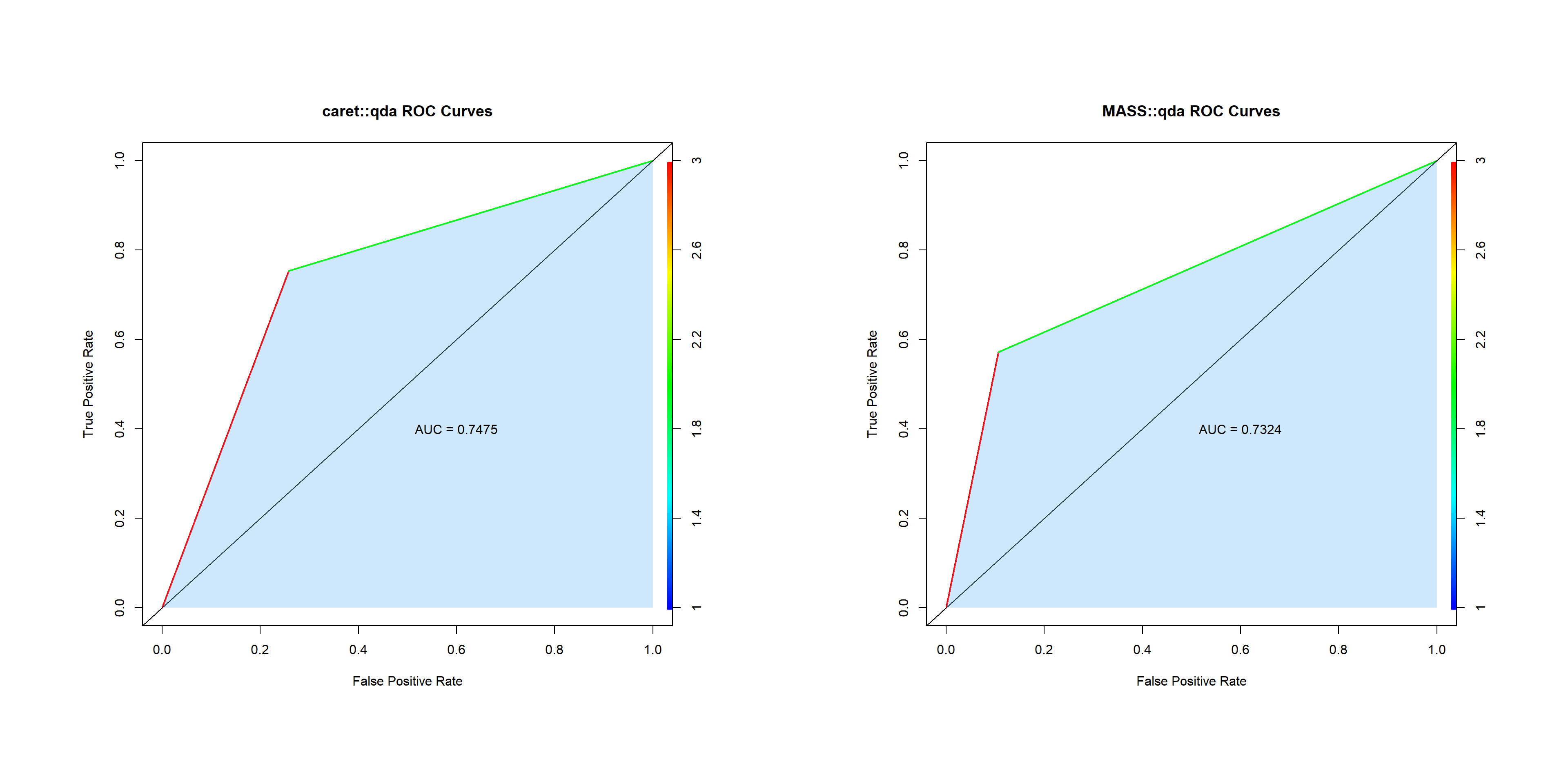
Balanced Accuracy : 0.7475
'Positive' Class : 0
Show/Hide Code
k <-10qda.predictions <-as.numeric(qda.predictions)pred_obj <-prediction(qda.predictions, test$good)# Compute AUC valueauc_val <-performance(pred_obj, "auc")@y.values[[1]]auc_val
# Set the number of foldsk <-10# Randomly assign each row in the data to a foldset.seed(1234) # for reproducibilityfold_indices <-sample(rep(1:k, length.out =nrow(wine.data_cleaned)))# Initialize an empty list to store the foldsfolds <-vector("list", k)# Assign each row to a foldfor (i in1:k) { folds[[i]] <-which(fold_indices == i)}#To store the error rate of each folderror_rate <-numeric(k)confusion_matrices <-vector("list", k)kappa <-numeric(k)# Loop through each foldfor (i in1:10) {# Extract the i-th fold as the testing set test_indices <-unlist(folds[[i]]) test <- wine.data_cleaned[test_indices, ] train <- wine.data_cleaned[-test_indices, ]# Fit the model on the training set qda_model <-qda(good ~ ., data = train, family = binomial)# Make predictions on the testing set and calculate the error rate qda.pred <-predict(qda_model, newdata = test, type ="response") predicted_classes <-ifelse(qda.pred$posterior[,2] >0.7, 1, 0)# Compute OER error_rate[i] <-mean((predicted_classes >0.7) !=as.numeric(test$good))# Compute confusion matrix test$good <-as.factor(test$good) predicted_classes <-factor(predicted_classes, levels =c(0, 1)) confusion_matrices[[i]] <- caret::confusionMatrix(predicted_classes, test$good)# Compute Kappa value kappa[i] <- confusion_matrices[[i]]$overall[[2]]# Print the error rates for each foldcat(paste0("Fold ", i, ": ", "OER:", error_rate[i], "\n"))}